
Binary log and Transaction cache in MySQL 5.1 & 5.5
The Binary Log
The binary log in MySQL has two main declared purpose, replication and PTR (point in time recovery), as declared in the MySQL manual. In the MySQL binary log are stored all that statements that cause a change in the database. In short statements like DDL such as ALTER, CREATE, and so on, and DML like INSERT, UPDATE and DELETE.
As said binary log transform multi thread concurrent data/structure modification in to a serialize steps of activity. To handle this, a lock for the binary log—the LOCK_log mutex—is acquired just before the event is written to the binary log and released just after the event has been written. Because all session threads for the server log statements to the binary log, it is quite common
for several session threads to block on this lock.
It is not in the scope of this discussion to provide a detailed description of the binary log, which could be found at http://dev.mysql.com/doc/refman/5.1/en/binary-log.html.
What it is relevant is that MySQL write "a" log and read "a" log, serializing what is happening in the MASTER in a multi thread scenario. Also relevant is that MySQL has to deal with different behavior in relation to TRANSACTIONAL and NON-TRANSACTIONAL storage engine, trying to behave consistently.
In order to do that MySQL had changes his behavior while evolving, so it changes the way he was and is using the TRANSACTION CACHE also creating not few confusion.
Transaction Cache
What is the Transaction Cache or TC? It is a "per thread" cache used by MySQL to store the statements that will be needed to be written in the binary log.
This cache is active ONLY when the Binary log is active, otherwise it will not be used, and, as it declare, it is a "Transaction" cache so used to store statements executed in a transaction, and that will be consistently flushed in the binary log serializing the multi thread execution.
But what if we also have non transactional storage engine involved in our operations? Well here is where the fun begins, and also where the difference in how MySQL acts makes our life quite complicate.
Actors involved (who control what)
The TC (transaction Cache) is currently controlled by few parameters, and it is important to have them in mind:
log-bin
o this variable is to enable the binary log, if not present all the structure related to it is not active;
binlog_cache_size
o The size of the cache to hold changes to the binary log during a transaction
binlog_stmt_cache_size
o this variable determines the size of the cache for the binary log to hold nontransactional statements issued during a transaction.
binlog_direct_non_transactional_updates
o This variable when enabled, causes updates to non-transactional tables to be written directly to the binary log, rather than to the transaction cache.
Binlog_cache_use vs Binlog_cache_disk_use
o Status Variables to use for checking the efficiency of the cache.
Binlog_stmt_cache_use vs Binlog_stmt_cache_disk_use
o Status Variables to use for checking the efficiency of the cache.
MySQL Transaction cache and MySQL versions
Ok let start trying to define some milestones, like what is what, in which version, and what works and what doesn't.
binlog_cache_size is present from the start but behave different, in:
5.1 controls the whole transaction cache
5.5.3 up to 5.5.8 controls both size of the statement and none cache
5.5.9 and newer controls only the transaction cache demanded to transactions
binlog_stmt_cache_size
5.1 not present
5.5.9 it controls the dimension of the transaction cache demanded to store the NON transactional statements present in a transaction.
binlog_direct_non_transactional_updates
5.1.44 Introduced. it is DISABLE by default. If enable it allows all statements executed, also AFTER a Transaction (we will see later what this means), to be directly flushed to the binary log without going to the TC. It has effect only if the binlog_format is set to STATEMENT or MIXED.
5.5.2 Introduced.
5.5.5 It was modify to be active ONLY if binlog_format is STATEMENT in any other case it is ignored.
This feature, regardless the MySQL version, create more problems then solutions, and honestly I think it should be removed, please see the bug (http://bugs.mysql.com/bug.php?id=51291) to understand what I mean. In any case it has now a very limited scope of action, and better to consider it as not present.
How the whole works
The first point to take in mind, is that the TC is used only during a transaction, also the new TCStatement, is suppose to store only statement that are issued during a transaction, and it will be flush at the moment of the COMMIT, actually it go the queue for acquiring the LOG_LOCK mutex.
All other statements will directly go to the LOG_LOCK mutex queue.
Said that let us see how the TC works and what it does and how.
In general terms when you mix the Transactional and NON-transactional statements these rules apply, unless the infamous
binlog_direct_non_transactional_updates is enable (only 5.1):
1. If the statement is marked as transactional, it is written to the transaction cache.
2. If the statement is not marked as transactional and there are no statements in the
transaction cache, the statement is written directly to the binary log.
3. If the statement is not marked as transactional, but there are statements in the
transaction cache, the statement is written to the transaction cache.
Interesting point here is what and how is define as NON Transactional or as TRANSACTIONAL, from reading the manual and the many reference we have that:
After MySQL 5.1.31
a statement is considered non-transactional if it changes only non-transactional tables;
a statement is transactional if it changes only transactional tables.
Finally a statement that changes both non-transactional and transactional tables is considered “mixed”. Mixed statements, like transactional statements, are cached and logged when the transaction commits.
Before MySQL 5.1.31
a statement was considered non-transactional if the first changes it makes change non-transactional tables;
a statement was considered transactional if the first changes it makes change transactional tables.
In term of code:
Before MySQL 5.1.31
Transactional:
BEGIN;
INSERT INTO innodb_tbl VALUES (a),(b);
INSERT INTO myisam_tbl SELECT * FROM innodb_tbl;
COMMIT;
NON-Transactional (the first command also if inside a declared transaction):
BEGIN;
INSERT INTO myisam_tbl VALUES (a),(b);
INSERT INTO innodb_tbl SELECT * FROM innodb_tbl;
COMMIT;
After MySQL 5.1.31
Transactional:
BEGIN;
INSERT INTO innodb_tbl VALUES (a),(b);
INSERT INTO innodb_tbl SELECT * FROM innodb_tbl;
COMMIT;
NON-Transactional:
INSERT INTO myisam_tbl VALUES (a),(b);
INSERT INTO myisam_tbl SELECT * FROM innodb_tbl;
Mixed:
BEGIN;
INSERT INTO innodb_tbl VALUES (a),(b);
INSERT INTO myisam_tbl SELECT * FROM innodb_tbl;
COMMIT;
A graph could help as well to understand what happens between threads and flush of the TC in the binary log.
In the graphs we have three treads running in parallel, remember that inside mysql the main entity is the THD "The THD class defines a thread descriptor. It contains the information pertinent to the thread that is handling the given request. Each client connection is handled by a thread. Each thread has a descriptor object."
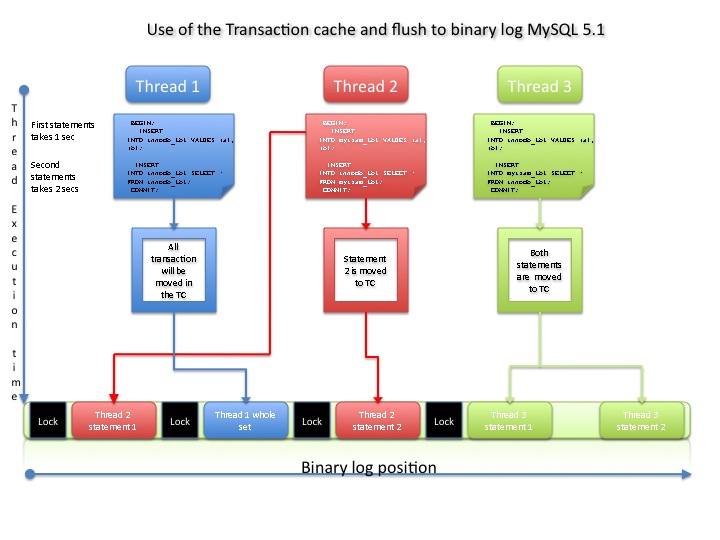
The first thread will do all the operations using TRANSACTION storage engine (InnoDB);
the second thread will use NON-TRANSACTIONAL (MyISAM) in the first insert, then TRANSACTIONAL (InnoDB);
the third statement will do first a TRANSACTIONAL insert and then will use it for a NON-TRANSACTIONAL.
In the first one I have assume the 5.1.31 and over behavior.
--------------------------------------------------------------
The three statements start almost at the same time, and none of them has data in any cache or buffer. Said that it is probably true that statement 1 in Thread2 will be executed (fully) faster, given it will take less as overhead, and giving that is the first statement in the THD2 transaction, it will be treated as NON-TRANSACTIONAL and directly sent to the binary-log's queue.
THD1 is fully TRANSACTIONAL, it will do his internal action then flush to binary-log.
Then THD2 had done also the second part of the operation TRANSACTIONAL and it is flushing it as well.
Last the THD3 which had first insert a record from TRANSACTIONAL table and then use it to populate the NON-TRANSACTIONAL.
Note
It looks more or less fine, isen't it? Well but assume that all the three THD share the InnoDB table and that as per default the ISOLATION LEVEL is Repeatable Read... Do you get it??
Actions and value on the MASTER will do and set values, that are potentially different from the ones in the SLAVE given the different order in the execution.
Immagine to have updates, instead insert and/or WHERE condition by values. Results could be different given the position, and remember, we are still talking about the STATEMENT replication given it is still the default ALSO in 5.5.
Finally remember that the issue it is NOT that THD1/2/3 could potentially change each other value, but the fact that they do something on the MASTER which could potentially different in the SLAVE.
That's it, the changes introduced in MySQL were done to reduce this wrong behavior, or to in some way try to keep consistency.
Let see what and how in the others graphs.
What about using binlog_direct_non_transactional_updates, will it helps?
I admit that I have exaggerated a little bit, in this example but my intention was to show how dangerous this option could be.
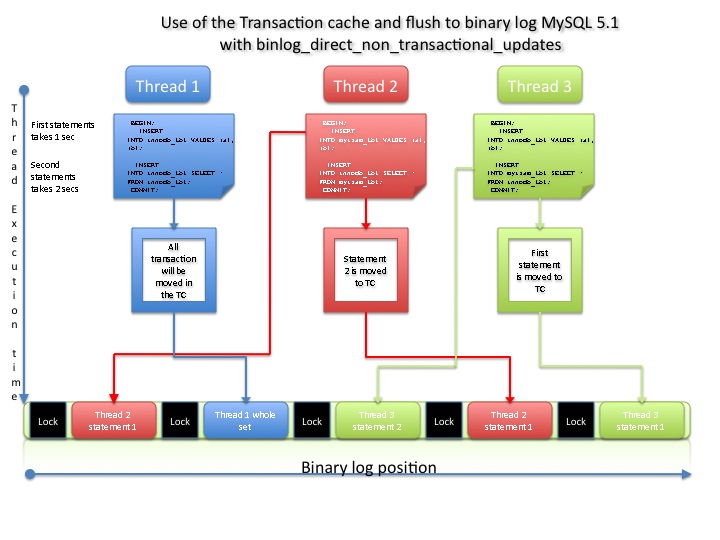
THD2 statement 1, as usual will be the first one, then THD1 consistently apply the whole set, but then it could happens that given the option set binlog_direct_non_transactional_updates THD3 will be faster in flushing the NON-TRANSACTIONAL statement, writing to the binary log before THD2, adding fragmentation and breaking the order in the binary log.
As said I have exaggerate a little, but theoretically this is very likely to happen in a standard context.
So in addition to the already found bug(s) (see the reference section), this option for me it is not really an additional help, but an issue generator.
Transaction Cache in MySQL 5.5
From MySQL 5.5.4 the TC is now divide in two parts, one control/store the TRANSACTIONAL statements, another store ONLY the NON_TRANSACTIONAL statements.
What does it means? In theory it means that any statement which was suppose to be part of a TRANSACTION but related to a NON-TRANSACTIONAL table (like statement at the start of a transaction), instead going directly to the binary log should be moved to the TC-statement, and then flushed when the TC is flushed.
The involvement of the binlog_direct_non_transactional_updates complicate a little all the scenario and in addition to that, it also create some major issue in the correct flush, so I am ignoring it here.
Let us see what happens using the new TC mechanism:
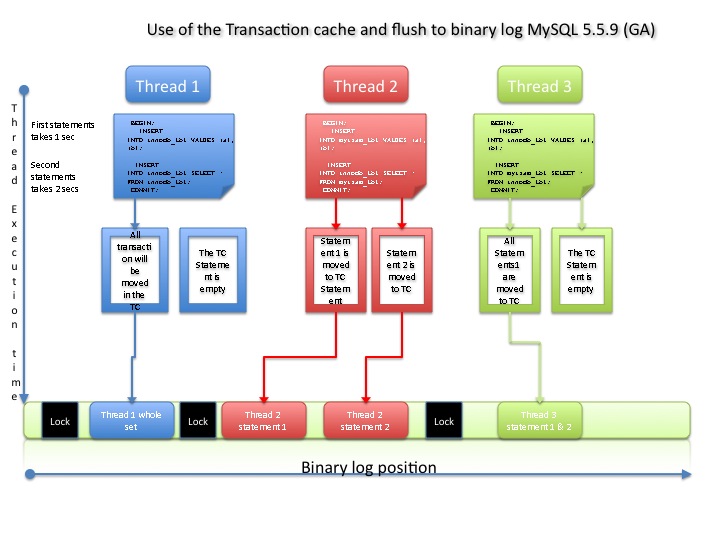
THD1 is as usual consistent in the way it flush to binary log. Arbitrarily I have decide that this time THD2 is taking a little bit more time like a millisecond, and that is enough for THD1 to acquire the LOG_LOCK before it.
The scope as you have probably guess was to make more ORDERED the graph, given that this time having one or the other flushing before or after will not really make any difference this time.
This because the TCStatement will be flushed (at least this is what I have seen and understood) when the TC is flushed.
Result is that the flush will take place using same the order on master and on the slave.
Finally THD3 also if will have the possibility to use the TCstatements it will not giving the fact that the statement using a NON-TRANSACTIONAL storage engine is NOT the first statement, so the mixed transaction will be placed in the TC as expected.
Conclusion
There was not so much to say from the beginning, to be honest, the TC and TCstatements are useful only for that case we do mix-transactions. The only significant changes are between after 5.1.31 and before and the introduction of the TCstatement. All the other tentative to add flexibility to this area, had in my vision increased bad behaviors.
It is easy for Master and Slave to store or modify data in a unexpected way, issue that any DBA face probably too often in MySQL.
I am not saying that all that cases should bring back to this specific issue, but for sure it is one of the less known and difficult to track, because many things do influence the how MySQL will flush to binary log.
The golden rule is, do not mix NON-TRANSACTIONAL and TRANSACTIONAL, but if you really have to do that, be sure of doing it in using 5.5.9 and above, which at least gives you more insurance of flushing to binary log the commands consistently.
Last notes
Remember that any statement NON-TRANSACTIONAL in the TC cache will be flushed on COMMIT or ROLLBACK, and that in the latest case a WARNING message should be written in the MySQL error log.
Note that I will post later (when I will have the time) some code and related raw data for documentation purpose.
References:
--------------
http://dev.mysql.com/doc/refman/5.1/en/replication-features-transactions.html
http://dev.mysql.com/doc/refman/5.1/en/replication-options-binary-log.html#sysvar_binlog_cache_size
http://bugs.mysql.com/bug.php?id=51291
http://www.chriscalender.com/?tag=large-transaction
http://mysqlmusings.blogspot.com/2009/02/mixing-engines-in-transactions.html