I decided to write this article after a discussion with other colleagues. We were wondering how and if the Percona Distribution for MySQL Operator(PDMO) could help a starting bu siness or a new project inside an enterprise. We were also wondering how it behaves in relation to already well established solutions, like Amazon RDS or Google SQL.
siness or a new project inside an enterprise. We were also wondering how it behaves in relation to already well established solutions, like Amazon RDS or Google SQL.
In fact, we often see analysis and benchmarking covering huge datasets and instances with very high levels of resources . But we tend to forget that any application or solution started as something small, and it is important to identify a database platform that allows us to scale from zero to a decent amount of load, while keeping the cost as low as possible.
This also happened while I was trying to get a bit more performance and stability out of Percona Operator for MySQL, and identify the possible minimal entrypoint and its usage.
Given all the above I decided to perform an investigation comparing the Percona Distribution for MySQL Operatorin the two most used cloud services, AWS and Google cloud. I am working on the Azure AKS and will publish results when available.
The investigation was taking in consideration three possible scenarios:
- 1S - I have a new website and my editorial system is X, my content is mainly static (Mainly Read Only)
- 2S - I have a new social platform, what should I use (OLTP style)
- 3S - I have a small application dealing with orders/payments, highly transactional (more TPC-C
And try to identify which is the best solution to use.
Of course, I do not pretend to cover all cases or even at 100% the one mentioned. But I think we can say a good 70% of cases nowaday match one of the three above
Tests
I have split the tests in three segment one for each major provider. This to be able to better compare the results, and following the assumption that if you are already registered on a platform you are more interested in comparing data locally than cross providers.
As usual for the tests I have used sysbench adapted version from here (https://github.com/Tusamarco/sysbench) and sysbench-tpcc style from here (https://github.com/Tusamarco/sysbench-tpcc). The customization for standard sysbench is in the table definition, and for tpcc like because I have improved the report layout.
Given we are talking about an entry point for a new product, I was considering two different scenarios:
- When dataset fits in memory
- When dataset doesn’t fits in memory
Data sets dimensions:
All tables are using InnoDB. Keep in mind that scenario 1S and scenario 2S use the same schemas (windmills_xx).
This is because normally when you start your new adventure, you do not have Terabytes of data in your database, but .. you plan to have them in the future. So most of the time you start with something very small and want to have a solution able to scale at least a bit.
I was also considering whether they need to be able to scale (a bit) so I was running tests using 64, 92,128, 256, 512 threads.
Finally each test was executed for 100 minutes, multiple times in different moments of the day and of the week. When multiple crashes happen the result will be zero.
Summarizing we have:
- 3 different scenarios
- Read Only (when write are so scarce that do not represent a variable)
- OLTP Read and write some are inside transaction some not (especially reads)
- TPC-C like load almost all inside transactions
- 2 Dimensions of dataset for each environment dimension
- Fits in memory (small)
- Large enough to cause more flushing and disk activity (large)
- 5 increasing number of threads
Assumptions
Assumptions and clarification before starting the review:
Q: Why are you using only one RDS instance instead of also spinning a Replica, we can also have the PDMO using only one node and reducing the cost impact.
A: We are testing minimal production solutions. Using only a node for PDMO is delivering a solution that has no High Availability. RDS with multi AZ is providing High Availability, with lower level of nines but still functional. See: https://aws.amazon.com/blogs/database/amazon-rds-under-the-hood-multi-az/ https://aws.amazon.com/blogs/database/amazon-rds-under-the-hood-single-az-instance-recovery/
Q: Did you tune any of the default settings coming with the service?
A: No. The assumption was that the provider is already providing optimised setup in relation to the solution offered.
Q: Did you modify the PDMO settings?
A: Yes. The basic config coming with the PDMO is set for testing on a very minimal/test setup. It is not production ready and should not be used in production as well. The settings for PDMO had been changed to match the resources available and the expected load. Nothing more than what we should expect from the service providers.
The layout
AWS
The following is a simplified layout of the tested solutions.
In general terms each solution spans across multiple subnets and AZ, each solution has a dedicated Application for testing and application connected directly to the closest endpoint provided. In case of EKS the nodes are distributed over 3 different subnets.
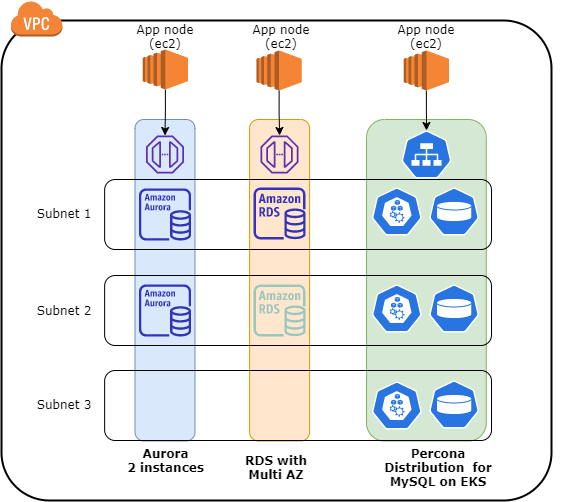
I am not reporting the whole internal details about how the Percona Distribution for MySQL Operator (PDMO) works, for that please refer to the documentation https://www.percona.com/doc/kubernetes-operator-for-pxc/index.html
The table below is reporting the high level description of the solutions tested:
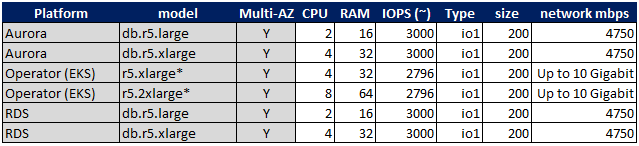
*For PDMO we had to use machines with more resources to host additional services like HAProxy and the operator itself. But the resources allocated for the database services were reflecting the ones used AWS for Aurora and standard RDS. Said that, while for this exercise we have used machines with a bit more resources, it is common practice to have one powerful host node with multiple database clusters to optimise cost and resource utilization, I will cover this better later in the cost section.
Down into the rabbit hole
A lot of graphs can be found here:
The name includes the test and the data set dimension.
In this section we will review the results of the tests by provider.
AWS
AWS is the most utilized Cloud provider and is also the one with more solutions when discussing Database services. I have tested and compared PDMO vs Aurora and standard RDS.
For clarity I am reporting two different sets of graphs for details. One is related to CPU, memory etc, the other is more MySQL specific.
In this context we have the following:
- aurora-eks-test1-instance-1; Primary node of the Aurora service
- aurora-eks-test1-instance-1-eu-central-1a; Secondary node of the Aurora service
- Mt-rds-kube-test; RDS instance
- pxc-cluster1-pxc-0 ; Pod serving the MySQL traffic for PDMO
As you may notice from the graphs, the Aurora service automatically swap/failover from a node to another more than once.
Checking Read Only traffic (scenario 1S)
Let us start with the easiest case, a simple new website with some editorial. As already mentioned this can be considered a Read Only case given the writes should be counted in few by minutes or even less.
Small Dataset
As previously mentioned, this case is the first baby step, when your DB is really at an infant stage.
Y axis reports operations/sec
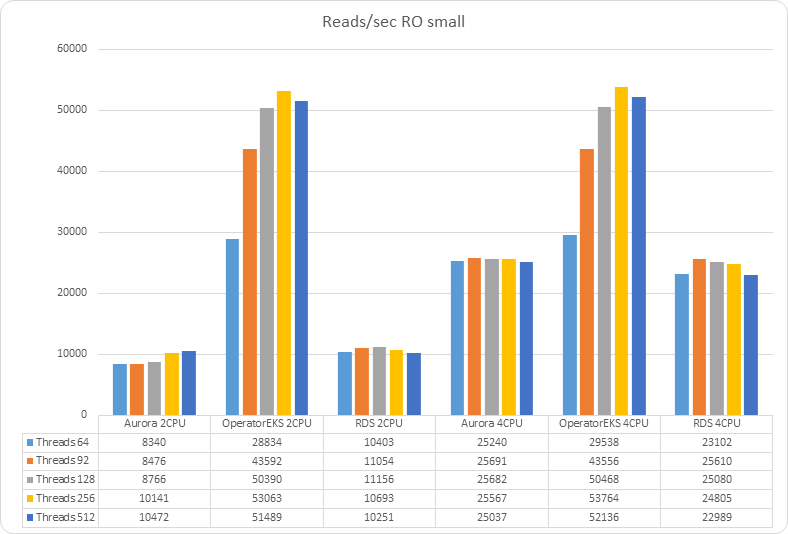
In case no matter if the dataset fits in memory or not, we can notice how the Percona MySQL operator is able to serve a higher amount of traffic in respect to the other AWS solutions. If we check what seems to be the limitation factor, we can see that:
2 CPU


4 CPU


We can see how in both cases the AWs solutions reach 100% of CPU utilization, limiting the number of operations they can execute in memory.
Also notice how the load was automatically moved from one Aurora instance to another during the tests (CPUs graph).
Large Dataset
Now let's see what happens if I am successful and my website starts to increase in content, such that my dataset does not fit in memory, and as such I will have MySQL evicting old pages from memory
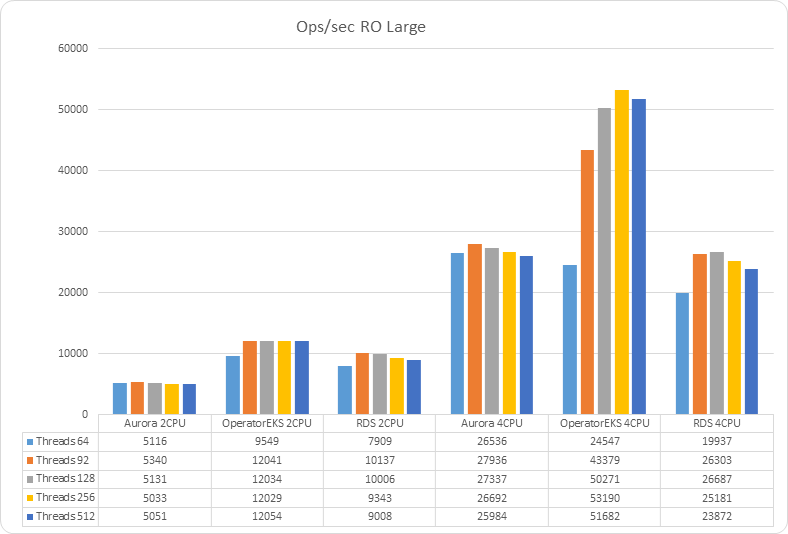
In case the dataset exceeds the dimension of the memory, PDMO is still performing significantly better than the other two solutions when using 4 CPUs. But it has a significant reduction of performance when using 2 CPUs.
2 CPUs


Disk Latency

The other relevant fact to notice is how the disk latency affected the reads for the PDMO when using a large dataset and 2 CPUs.
This negative effect doesn't show up in case of 4 CPUs
4 CPUs


Also in the case of 4 CPUs we see the same behavior, with AWS solutions not able to scale and failing to serve traffic.
Disk Latency

Checking OLTP (scenario 2S)
This case is obviously more complicated given the writes and transactions. The level of reads is still high, around 93% but all operations are enclosed inside transactions.
In this case we MUST review in parallel the SMALL and LARGE dataset to better understand what is happening.
Operation/sec
 |
 |
As you can see the solution using the Operator is overperforming in the case of small and large datasets. While AWS solutions are still suffering from the same CPU limitation we have seen in the read only load.
2 CPUs small


2 CPUs Large

We can observe how CPUs resources in the case of AWS solutions are always at 100%, while PDMO can count on resource scaling.

2 CPUs large Disk Latency

4 CPUs small


4 CPUs Small Disk Latency

4 CPUs large


4 CPUs Large Disk Latency

With 4 CPUs available the Aurora solution can count in a bit more “space” to scale, but still not enough to result as efficient as PDMO.
As for the read only, we can see the disk latency significantly increase in the case of Large dataset, especially for the PDMO solution.
It is interesting to see how Aurora is penalized not only by the CPU utilization but also by a very high disk latency.
Latency 95pct (lower is better)
-OLTP-small-_20.png) |
-OLTP-large_19.png) |
Latency metrics reflect the operation trend, highlighting how the low CPU-resources/Disk-latency affects all solutions, especially in case of large datasets.
Checking TPC-c (inspired) load (scenario 3S)
Also in this case we have that all the queries are encapsulated in a transaction and in this kind of test the read and write operations are close to being split at the 50% mark, so we expect to see a significant load on disk write operation and for the data replication mechanism.
Operation/sec
 |
 |
In this scenario PDMO results to be more penalized when the dataset is larger than the available memory. In some way this is expected, given the level of writing is such that the solution pays the cost of the virtual-synchronous replication mechanism used in PXC.
If we check the details we can see:
4 CPUs Large


4 CPUs Disck Latency

As we can see the PDMO node receiving the direct load is not crazy loaded, while the disk latency is higher than RDS with an average of 4ms write and 8ms for read operations.
But that is not enough to justify the delta we have in performance loss. What is preventing the solution from being as efficient as the other two?
PXC flow control

PDMO is using PXC as technology to offer service high availability and full data consistency. This means that the cluster must certify and apply all writes in any node at each commit, with the increase of the write operations this solution also increases the pressure on the replication layer and if any node has a delay in applying the write, that delay will affect the efficiency of the whole cluster.
In our case we can see that nodes pxc-0 and pxc-2 are on hold for pxc-1 to perform the writes.
We also have as side effect the increase of the sending queue on the primary node (pxc-0)

Latency
-TPCC-small-_22.png) |
-TPCC-large_21.png) |
Latency is just confirming us the picture we had from the operations.
What should I pick?
Before indicating what should be a good solution for what, let us talk about costs.
Costs
To discuss the cost, we need to make some assumptions.
The first assumption is that we need to calculate the cost by solutions and not by node. This is because we cannot consider a solution with a single node for PDMO or Aurora. To be effective both require their production minimum requirements, which for Aurora is two nodes and for PDMO given is based on PXC 3 nodes. Given that calculating by node is a fictitious artifact, while calculating by solution gives you the real cost.
The second assumption is that we can have more PDMO solutions running on the same Node. Which means we will have a better relation cost/benefit in utilizing larger nodes and use them to run multiple PDMO solutions. In that case, the only cost that will need to be added is the cost of the attached EBS volume per delivered POD.
Let me provide an example of PDMO calculation.
If I consider the minimal Node resource requirements, as we did for these tests, I will need to have:
|
Solution |
Node Type |
Monthly Cost |
|
PDMO 2 CPU |
R5.xlarge |
1,609 USD |
|
PDMO 4 CPU |
R5.2xlarge |
2,274 USD |
But if we use a larger node that can host multiple PDMO like a r5.4xlarge (16 CPU 128GB) that can host multiple PDMO :
|
Solution |
PDMO instances per node |
Monthly Cost - full solution for PDMO |
|
PDMO 2 CPU |
3 |
1,202 USD |
|
PDMO 4 CPU |
2 |
1,803 USD |
As you can see also if a solution based on r5.4xlarge has higher absolute cost per node, the fact you can run multiple PDMO in a node allows you to reduce the cost in a significant way by solution.
Said that let us summarize the cost of the solutions:
|
Solution |
Node Type |
Monthly Cost |
|
Aurora* 2 CPU |
db.r5.large |
$6,323.30 |
|
Aurora* 4 CPU |
db.r5.xlarge |
$6,834.30 |
|
RDS 2 CPU |
db.r5.large |
$1,329.80 |
|
RDS 4 CPU |
db.r5.xlarge |
$1,753.20 |
|
PDMO 2 CPU (single instance per delivered node) |
r5.xlarge |
$1,609.20 |
|
PDMO 4 CPU (single instance per delivered node) |
r5.2xlarge |
$2,274.96 |
|
PDMO 2 CPU (multiple instance per delivered node) |
r5.4xlarge |
$1,202 |
|
PDMO 4 CPU (single instance per delivered node) |
r5.4xlarge |
$1,803 |
* For Aurora we had to include an average number of operations based on the test executed. Please refer to: https://calculator.aws/#/createCalculator/AuroraMySQL
As you can see PDMO is just a little bit more expensive than RDS when deployed in single instance mode. But it also provides better performance in most cases and always has a higher level of High Availability, given PXC is used in the background.
There is no discussion if you can use multiple PDMO on larger nodes, in that case the cost goes lower than RDS.
So what to pick
Read-only
Choosing is not only based on performance, but also how efficient the solution we pick is to perform the maintenance of our platform. In this regard both operator and Aurora offer a good level of automation. But PDMO was always performing better than the other two solutions. On top of that Aurora based solutions are more expensive than the others, so in the end, for me, choosing PDMO is the logical thing to do, being ready to eventually do a small scale-up in case I need more resources. This is another advantage of PDMO, I can eventually decide to add fragments of the CPU cycle, without the need to move to a higher and more expensive system.
OLTP
In this case there is no doubt that PDMO is the solution to go to. Aurora can be seen as a possible replacement given that the RDS solution has a lower level of HA in respect to the other two. But as we know the Aurora costs are higher than any other compared solutions here.
TPCC
RDS is the solution to go to serve the load and save the money, but you will have a lower level of HA. If you are willing to cover the cost Aurora is the solution offering you good performance and high level of High Availability.
Finally we can say that PDMO was penalized by the replication/certification mechanism in use in PXC but, the significant saving in terms of cost can justify the adoption, especially considering that with a limited scaling up in resources we can gain more traffic served. Scaling will never be as expensive as if we adopt Aurora as a solution.
Conclusions
Trying to identify an entry point solution for a starting activity is harder than choosing a platform for something already well defined. There is a lot of uncertainty, about the traffic, the kind of operations, the frequency of them, the growth (if any).
In my opinion there are already so many variables and things that can possibly go wrong, that we should try to adopt, if not the safest solution, the one that gives us a good level of confidence in what we will be able to achieve.
I was not surprised to see products such as Aurora shine when we have Tpcc like load, but I was pleased to see Percona solution with the operator performing in an admirable way.
Of course I was not using the settings coming from the vanilla installation, given they are for testing. So if you install PDMO in production you MUST change them (see here for my cr.yaml) and I was counting on version 1.9.0 at least, without which PDMO is not even in the game.
But it is obvious that Percona is on the right path, with a long road ahead, but we it is moving in the right direction.
Percona Distribution for MySQL Operatoris still a baby, but is growing fast, and the more we have people using, testing and providing feedback, the fastest Percona will be able to provide software that not only early adopters implement, but also the more conservative ones can use for their production.
References
Disclaimer
My blog, my opinions.
I am not, in any way or aspects, presenting here the official line of the company I am working for.
Comments
If you have comments or suggestions please add them to the linkedin post