My first impression on Mariadb 10.4.x with Galera4
MariaDB 10.4 has being declared GA, and few presentations on Galera4 in the last conferences were hold.
So, I thought, it is time to give it a try and see what is going on.
It is not a secret that I consider the Codership guys my heroes, and that I have push for Galera as solid and very flexible HA solution, for many years.
Given that my first comment is that it was a shame to have Galera4 available only in MariaDB, I would have preferred to test the MySQL vanilla version for many reasons, but mainly because the MySQL/Oracle is and remain the official and main line of the MySQL software, you like it or not, and as such I want to see how the Galera4 behave with that. Anyhow Codership state that the other versions will be out AFTER the summer, and I hope this will be true.
To test the new version given I do not have the vanilla MySQL, I decide to use the other distribution coming from Percona. At the end the test where done comparing MariaDB 10.4.x with PXC 5.7.x. In short Galera4 Vs Galera3.
I setup on the same machines the two different software, and I configure as close as possible. Said that I did 2 main set of tests: Data ingest and OLTP, both running for 90 minutes, not pushing like hell, but gently simulate some traffic. Configuration files can be found here.
Galera4 stream replication was disable, following the Codership instruction (wsrep_trx_fragment_size=0).
Test1 Ingest
For the ingest test I had use my stresstool application (here) with only 10 threads and 50 batch inserts each thread, the schema definition is in the windmills.json file.
As always, an image says more than many words:
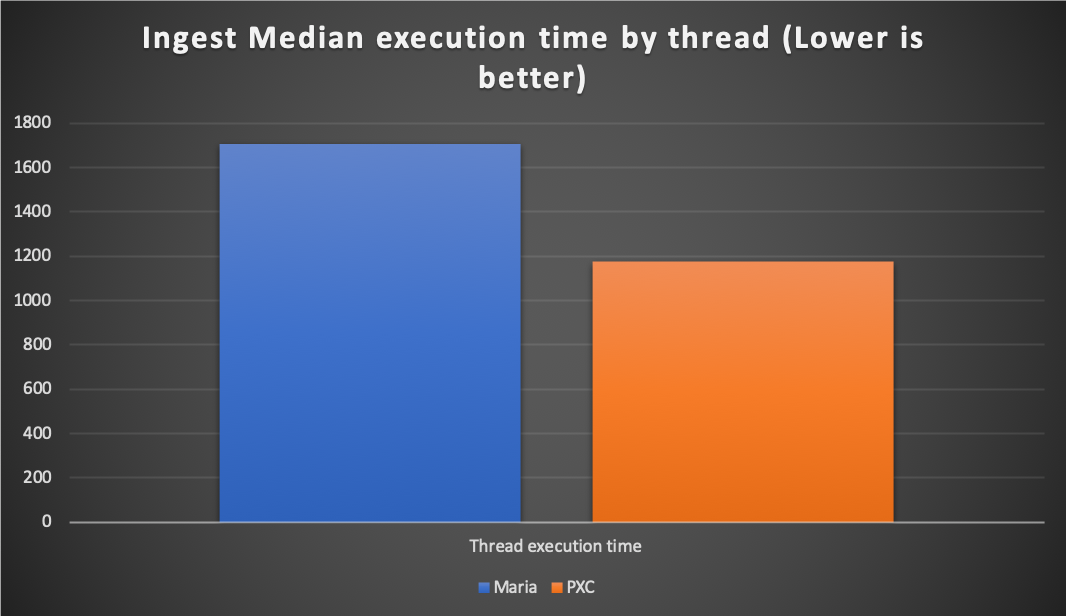
In general terms, PXC was able to execute same load in less than MariaDB.
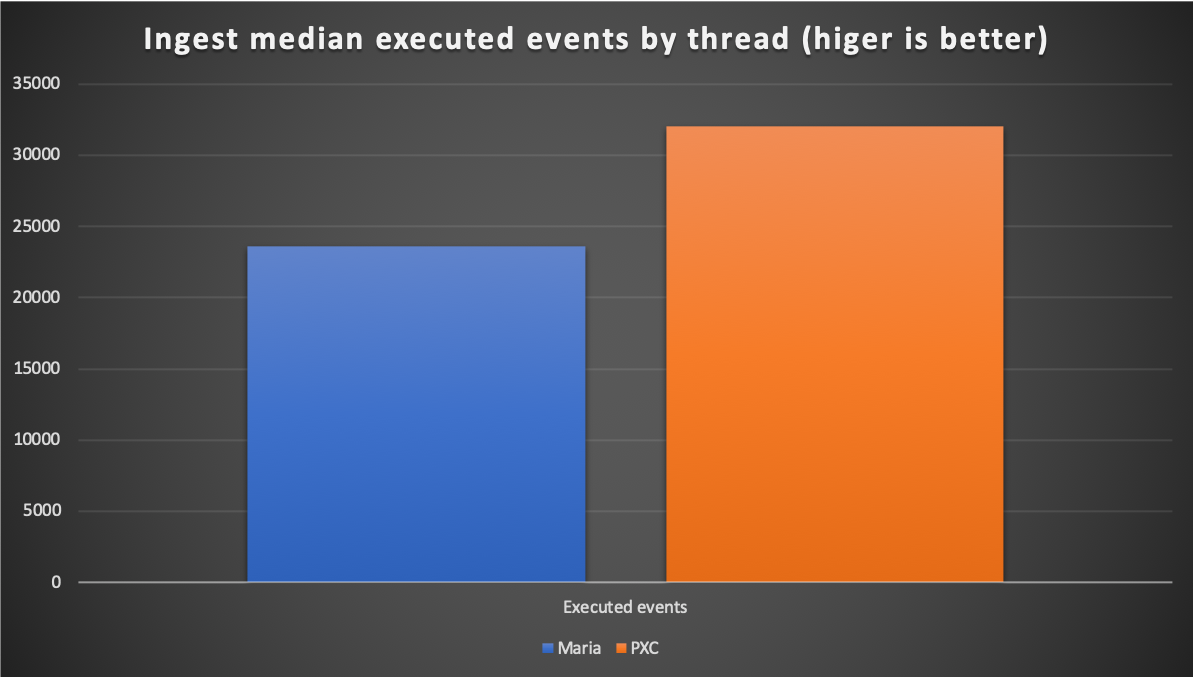
And PXC was able to deal with a higher number of events per thread as well.
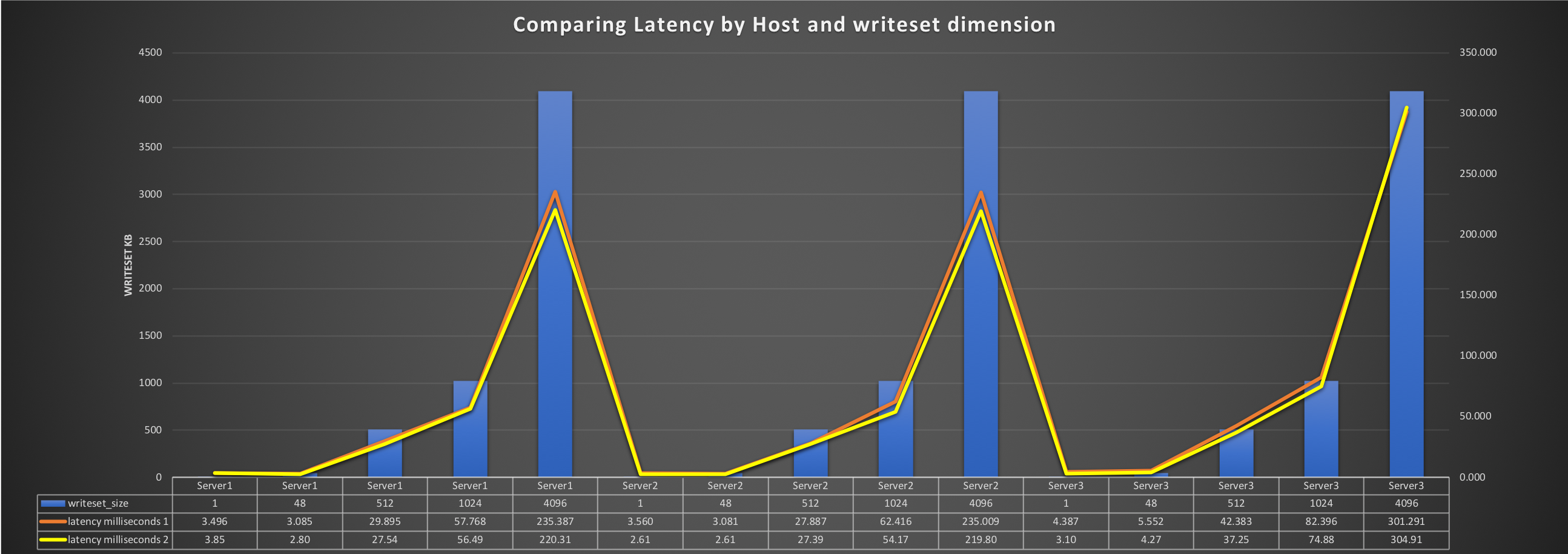
The average galera latency was around 9ms in the writer and around 5ms for the receivers in PXC. With same load, same machines, same configuration:

The latency in MariaDB was significantly higher around 19ms for the writer, and between 9 and 5 ms for the receivers.

In short overall PXC 5.7 with galera3 was performing better than MariaDB 10.4 with galera4.
The amount of data on transmitted and received on PXC was higher (good) than Mariadb:
PXC:

MariaDB:

OLTP
For oltp test I have sysbenc with oltp r/w tests, 180 threads (90 from two different application nodes), 200K rows for table, 40 tables and 90 minutes run.
Let see what happened:

PXC was performing better than MariaDB, executing more writes/s and and more events_thread/sec.
Checking the latency, we can see:

Also in this case PXC was having less average latency than MariaDB in the execution.
What about galera?
For PXC/Galera3, the average galera latency was around 3.5ms in the writer and less in the receivers:

In this case the latency in Galera4 was same or less of the one in Galera3:

Also analyzing the MAX latency:
Galera3

Galera4

We can see that Galera4 was dealing with it much better than the version3.
I have done many other checks and it seems to me that in the OLTP, but I do not exclude this is valid for ingest as well, Galera4 is in some way penalize by the MariaDB platform.
I am just at the start of my investigation and I may be wrong, but I cannot confirm or deny until Codership will release the code for MySQL.
Conclusions
Galera4 seems to come with some very good new feature, please review Seppo presentation, and one thing I noticed it comes with optimized node communication, reducing the latency fluctuation.
Just this for me is great, plus we will have stream replication that can be very useful but I have not tested it yet.
Nevertheless, I would not move to it just yet. I would wait to have the other MySQL distribution supported, do some tests, and see where the performance problem is.
Because at the moment also with not heavy load, current version of PXC 5.7/Galera3 runs better than MariaDB/Galera4, so why I should migrate to a platform that locks me in like MariaDB, and do not give me benefit (yet)? Also considering that once Galera4 will be available for the standard MySQL versions, we can have all the good coming from Galera4, without being lock in by MariaDB.
A small note about MariaDB, while I was playing with it, I noticed that by default MariaDB comes with the plugin level BETA, which means potentially run in production code that is still in beta stage, no comment!
References
https://github.com/Tusamarco/blogs/tree/master/Galera4
Seppo presentation https://www.slideshare.net/SakariKeskitalo/galera-cluster-4-presentation-in-percona-live-austin-2019

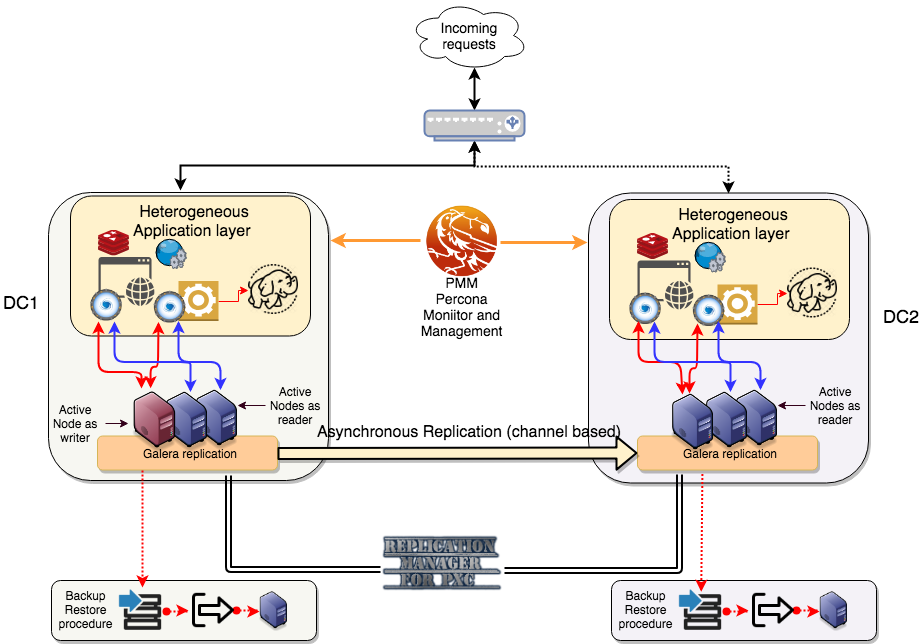
 Let's talk about MySQL high availability (HA) and synchronous replication once more.
Let's talk about MySQL high availability (HA) and synchronous replication once more.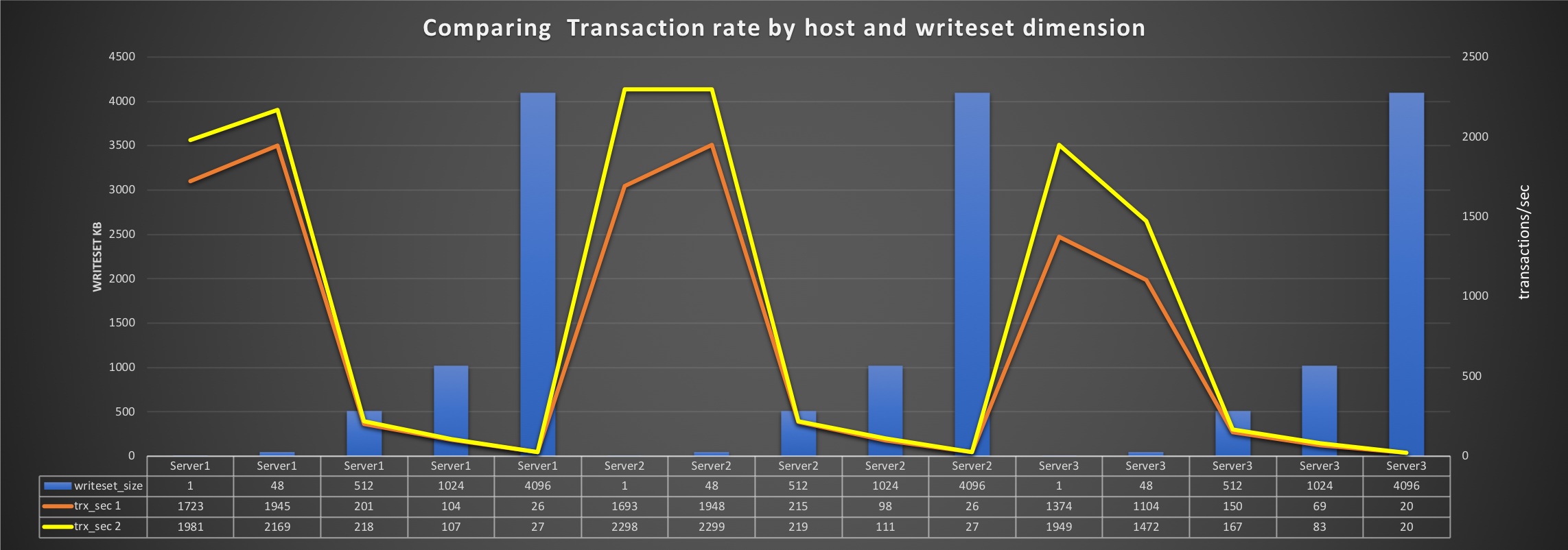
 MySQL High Availability. Shutterstock.com[/caption]
MySQL High Availability. Shutterstock.com[/caption]